A pragmatist’s reflections on data quality

If a picture is worth a thousand words, what picture does the collective brainpower of a thousand thought leaders paint for open contracting in Latin America? I’ll give you 981 guesses, one for each participant at this year’s ConDatos. Spoiler alert: you should be pumped.
Earlier this month, representatives from the public, private, and third sectors, along with general data enthusiasts (read: nerds), from across Latin America convened to discuss the the future of data in the continent. Throughout the week, which included both the AbreLatAm unconference and the ConDatos event, practitioners and theorists alike explored their most pressing data challenges and generated innovative, pragmatic solutions to tackle those challenges. Conversations tended to follow one of two “choose your own adventure”-esque threads: “If you have the data and don’t know what to do with them, turn to page 10” and “If you just can’t get the data you need, turn into a puddle of tears.” As a data scientist (for the record, I prefer the term “data wizard”) who straddles both paths, I was thrilled to have the chance to take advantage of the collective expertise of the participants to brainstorm pragmatic swords to defeat these data dragons.
Here are a few of the key strategies I took away from our week in Bogotá for working smarter, not harder.
Data quality challenges are like Hydra: Slay one problem, and two more will pop up
Real talk for a minute: though my data dork daydreams revolve around impeccably interoperable, remarkably robust, delicately documented datasets, the pragmatist in me pummels those fantasies into submission faster than you can say, “machine readable.”
The reality is that development data, as they often come from areas with limited resources, technology gaps, and political and social contexts that are less than data-friendly, are particularly vulnerable to issues of availability, accessibility, and quality.
That leaves us with two options: 1.) huffing and puffing and trying to blow these data challenge houses in or 2.) accepting that these issues, though serious and valid, are unlikely to ever be resolved, and planning a strategy to work around, and not against, them.
Unsurprisingly, I am partial to the second route. Thankfully, I was not alone in praise of pragmatism. Sessions like “¿Cuáles son las brechas de acceso a la información y cómo cerrarlas?” (“Where are there information access gaps, and how do we close them?”) sparked lively conversations on identifying and generating practical strategies and tools to combat data coverage issues. At the OCP, we are excited to apply what we learned from these sessions to craft pragmatic approaches to dealing with the unique data accessibility and quality issues of each of the thirty six countries we are supporting in their open contracting efforts.
Perfect is the enemy of good
When you think about it pragmatically, an event summary blog is really not that difficult to write. You just think about what happened and what you learned, and jot down some notes in words that will make sense for your audience. Maybe you come up with a pun or two, and everything is all write.
How is it, then, that this blog took me two whole weeks to submit for proofreading? Because idealist me is convinced that whatever I write is leaving out critical learnings, opportunities to explicitly highlight the amazing work of the presenters and attendees, and, most importantly, windows for word play.
One of my major takeaways from the “Calidad de los datos abiertos” (“Open data quality”) session was that we need not strive for perfection. In the first place, “perfection” is a terribly nebulous concept; what is a “perfect” product or dataset depends heavily on the unique needs and preferences of each user. Besides, even if we could somehow arrive at a common understanding of “perfect,” it is probable that the cost of achieving such a level would far outweigh the benefit. In this way, I have begun to think of “perfection” as a diamond: commonly thought of as the zenith of quality, but pragmatically worthless.
Maybe, then, what we need to do is focus on figuring out what is “good enough,” as defined within a specific context in which we are meeting the specific set of needs of a specific user group. This approach involves fostering feedback loops to pinpoint what users really need, and then allocating resources to make sure we meet those needs.
We put this theory to use during ConDatos at an open feedback meeting regarding the upcoming update of the Open Contracting Data Standard (OCDS). At this meeting, we heard directly from users about opportunities to revise the standard to better suit implementer needs. Such opportunities included the reworking of existing data fields and the addition of new fields that will capture currently unavailable data needed to achieve the four use cases for open contracting.
With this in mind, from here on out, instead of pining for perfection, I’ll calibrate my work by weighing the cost of marginal increases of effort against the corresponding marginal increase of pragmatic returns.
Data matter, but only the right data count
One tenant of the utilitarian approach outlined above is making smarter decisions about where to allocate scarce resources such as time and human capital. Though the concept of “big data” has become the sexiest idea across the data community, we really should be salivating over big data’s steamier twin, “smart data.”
As data creators and users, we must accept the challenge of checking our work against a central idea of the Data Revolution: “Data for what, data for whom?” Sure, there’s nothing like a big, strong dataset to keep you warm at night, but what will really take care of user needs is a smart, “good enough” dataset that allows you to accurately and completely extract the knowledge you need, without overwhelming and confusing the user.
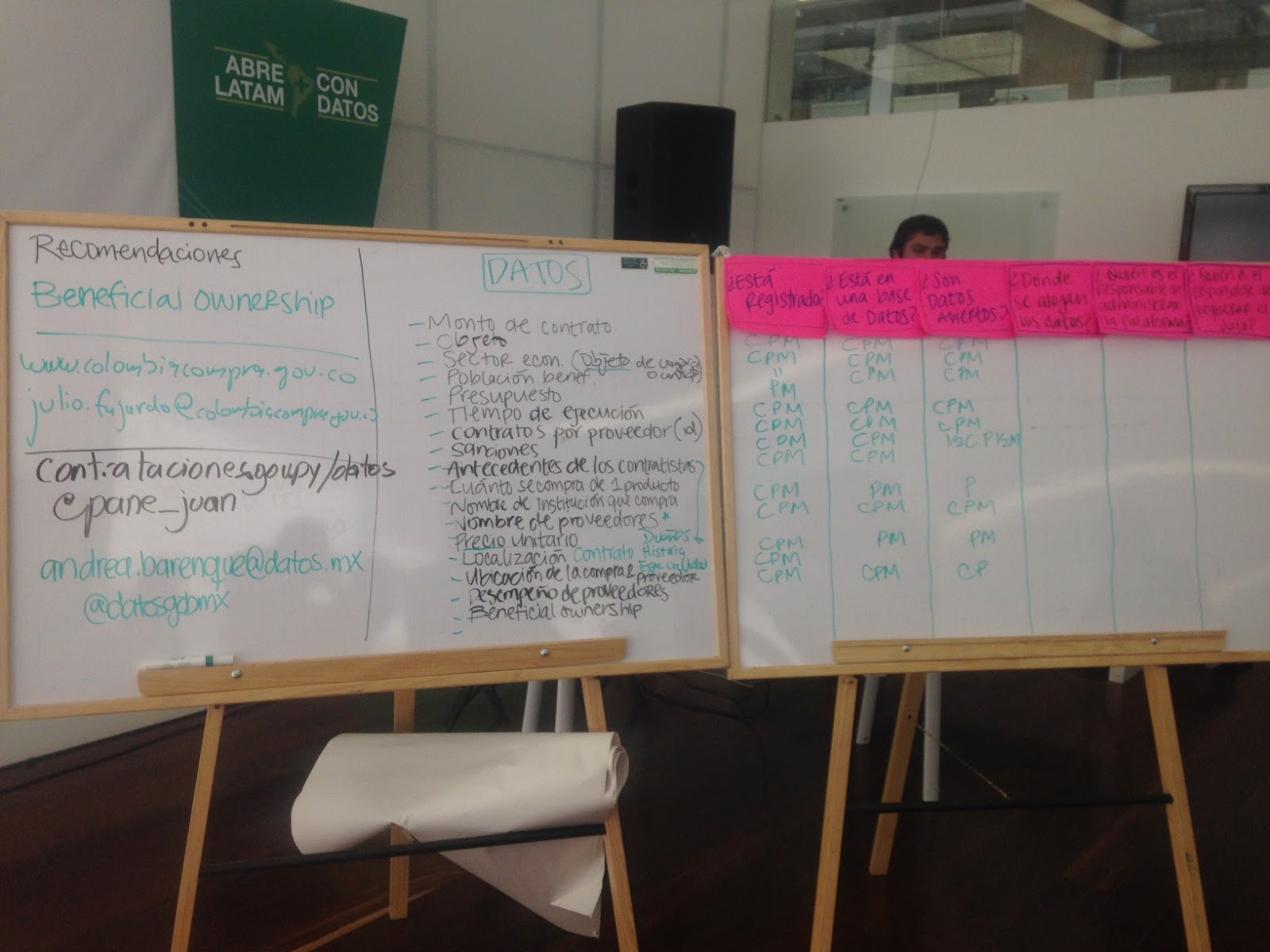
We strategized our agenda for our own two main events in Bogota, a half-day private workshop with the Colombia Compra Eficiente team and a joint open contracting workshop co-organized with World Bank as part of the main ConDatos agenda, around this idea. At these interactive sessions, we split into small groups to take a deep dive into how to link up use cases (or intended impacts) with concrete data needs (or inputs). In plenary, we then consolidated these data needs into centralized lists. Kevin Durant would say, these fields are the real MVPs of the data world. The final result of this activity, which, unfortunately, is not in machine readable format (please don’t ban me from the next ConDatos), is below.
Figure 1: Prioritized Data- Colombia Compra Eficiente Workshop
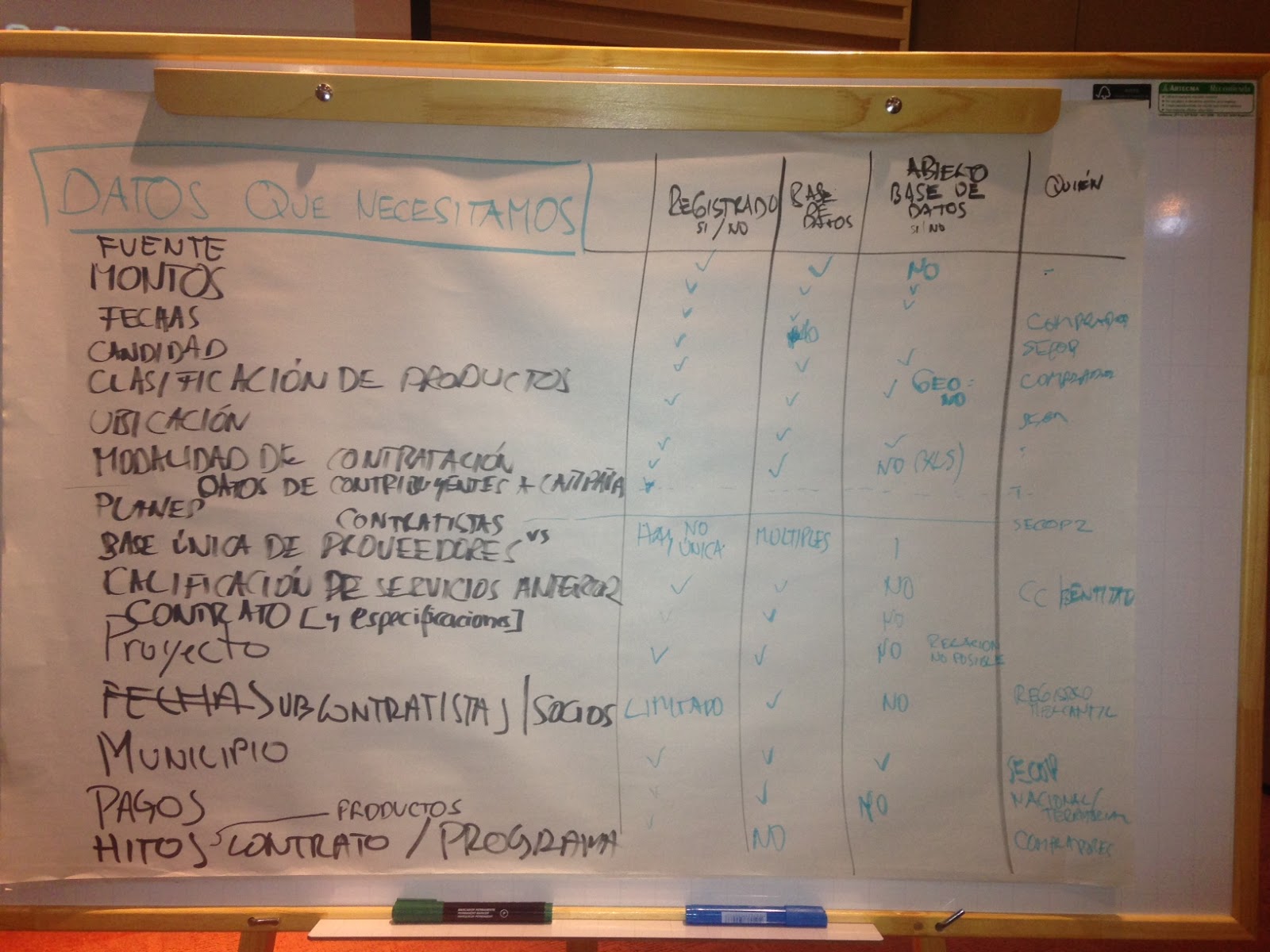
Translation:
| Data we Need | Tracked? | In database? | Open? | Who is responsible? |
| Source | X | X | No | – |
| Amount | X | X | X | Buyers |
| Date | X | X | X | SECOP |
| Quantity | X | No | X | Buyers |
| Product Classification | X | X | X | SECOP |
| Location | X | X | X, but not geolocated | – |
| Procurement Method | X | X | X | – |
| Campaign and Contributions Data | X | X | No | – |
| Planning Data | SECOP2 | |||
| Centralized (One Single) Database of Contractors and Providers | There isn’t a single centralized database | In multiple databases | X | |
| Prior Service Rating | X | X | No | CC/ Entity |
| Contract (and Specifications) | X | X | No | |
| Project | X | X | No, Relation not possible | |
| Subcontractors/ Associates | Limited | X | No | Registry |
| Municipality | X | X | X | SECOP |
| Payments | X | X | No | National/ Territory |
| Contract and Program Milestones | X | No | Buyer |
Figure 2: Prioritized Data- ConDatos Open Contracting Workshop
Translation:
Note: “C” stands for Colombia, “P” for Paraguay, and “M” for Mexico.
| Data we Need | Tracked? | In database? | Open? |
| Contract amount | |||
| Objective | CPM | CPM | CPM |
| Economic sector | CPM | CPM | CPM |
| Number of beneficiaries | ¨ | CPM | CPM |
| Budget | PM | ||
| Project period | CPM | CPM | CPM |
| Provider ID | CPM | CPM | CPM |
| Sanctions | CPM | CPM | M, somewhat in C, somewhat in P |
| Supplier history | |||
| Quantity | CPM | ||
| Buyer name | CPM | PM | P |
| Provider name | CPM | CPM | CPM |
| Unit price | |||
| Location | CPM | PM | PM |
| Buyer and provider location | CPM | ||
| Provider performance | CPM | CPM | CP |
| Beneficial ownership |
These lists represent a concrete guide we can follow to strategically plan data collection and analysis in government contracting. As we are constantly striving to make data more actionable, we are thrilled to have created this feedback loop and find out what the people really need. We will continually refer to these data wishlists as we continue both the OCDS upgrade and data publication planning with our implementing partners.
So, what can the open contracting community look forward to over the next year? The key here is shifting from expecting “more” to expecting “better”; better feedback loops, better data, and better tools. Does 2017 promise to be the best year for open contracting yet? You’d better believe it.