Using tabular versions of OCDS to generate JSON data

This post in our technical series explains how to generate an JSON in the Open Contracting Data Standard from tabular data.
There isn’t a single approach when a publisher, for example, a public procurement agency, decides to start a transparency process by implementing the Open Contracting Data Standard (OCDS), and converting the data managed by their e-procurement systems into OCDS. The architecture and tools chosen to implement this process will strongly depend on the internal technical capacity to build the Extract, Transform and Load (ETL) procedures, or evaluate the need to hire external consultants or development teams.
From the variety of tools available at the building stage, chances are that SQL is one of them. In public institutions, it’s common to have an IT department that deals with the administration of internal systems. Members of the IT department may or may not have knowledge of programming languages and frameworks, but it’s almost a given that they would be familiar with some DBMS (DataBase Management System) and its SQL flavor.
Even when programming gives more flexibility when building systems, it’s totally possible to develop a full transformation process using SQL only. Now, you may know that producing JSON from SQL queries and functions is technically possible but takes a lot of time and effort to achieve in real life; especially with large instances of JSON, as OCDS can have. Thankfully, there is an alternative: producing tabular results that can be easily transformed into one of the OCDS secondary serialization formats, and then converting the files to JSON using an existing transformation tool.
In this blog, we will present the steps to use this method. At the helpdesk, we have been fortunate to follow two real-world cases in which the approach is already being implemented in practice: first we have the case of Paraguay’s DNCP (the national procurement agency), where the transformation process is being written in SQL to take advantage of the local resources for future maintenance; and the second case is MIGA (Movimiento de Integración Gastronómico Boliviano in Spanish), a Bolivian NGO that wants to use OCDS to share their collected procurement data but also have the data in a friendlier format for non-technical users.
The approach and uses
We’ll start by explaining what the OCDS secondary serializations are. To be compliant with OCDS your data must be published in JSON format, but the standard allows alternative formats to be published alongside JSON. Secondary serializations can be represented in any tabular file format like CSV, but the transformation between the nested structure set by the standard to a tabular format is not straightforward.
OCDS documentation proposes two approaches for the transformation: simplified single table, in which the output is a single table, and multi-table with the output is distributed into several tables. Ideally, we would like a multi-table approach if we want to transform all the available fields in the data.
The figure below gives a glimpse of how the transformation should be done from a single JSON source.
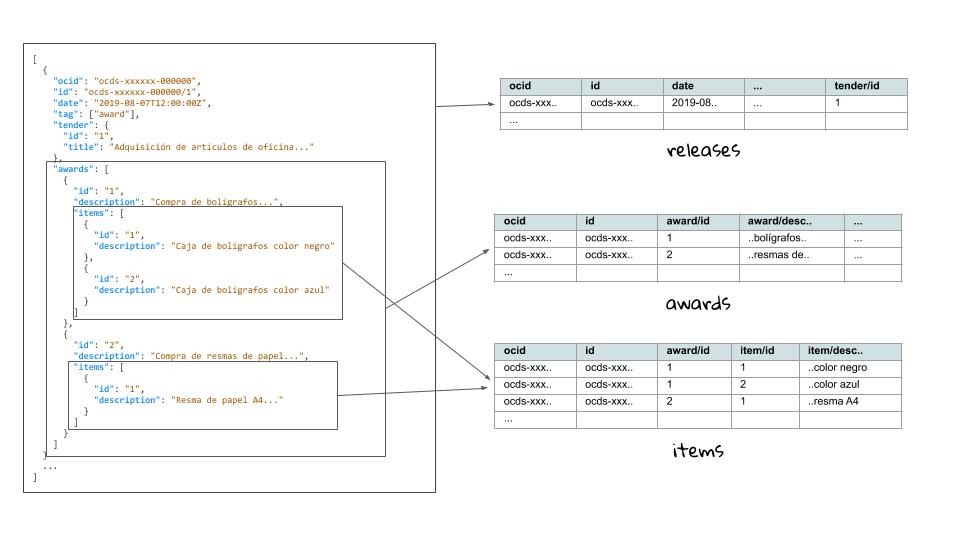
As you can see, arrays with multiple items within the JSON structure can be represented as tables of their own. The linkage between tables is done through keys shared between tables, where the ocid and release id are shared between all tables and additional ids are used where needed, as in the items table which has a reference to the awards table through the awards/id column.
Since the explanation can be quite extensive, we will not dive into the specifics of the JSON to CSV transformations. You can read more about it in the standard documentation, and we recommend this entry in the Flatten Tool documentation that explains the transformation procedure for generic JSON.
As said before, using SQL to produce JSON can be next to impossible, but producing results that can be stored as CSV files that look like the example above should be significantly less difficult. The difficulty of writing the SQL scripts needed to achieve this would depend on the size and complexity of the source(s) system(s). Below is an example taken from Paraguay DNCP’s open source project:

Once we have the scripts in place, the next step will be to transform these CSV files into JSON. There is more than one tool to do this, but we recommend the Flatten Tool. The Flatten tool is a generic JSON to CSV/Excel transformation tool (and vice versa) that can be used as a Python library and also provides a CLI interface. The transformation takes a single line command; you can go to the documentation of Flatten Tool for OCDS for use examples.
The following figure describes the architecture to do the exports from source to OCDS as explained:
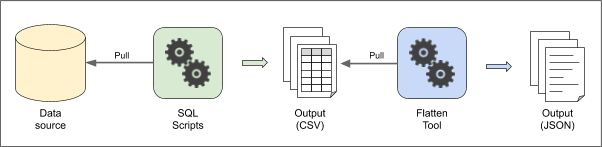
In Paraguay, the DNCP is currently extending the architecture proposed to upgrade their publication to OCDS 1.1. After the last step, the JSON output is inserted into an Elasticsearch server, to provide an API service as well as static files for direct downloading. It is expected that any future modifications needed because of new data or upgrades could be done in the SQL scripts, so the DNCP can use their own internal resources for maintenance of the process. The project has an open source version that can be found here.
Another potential use of the tabular version of OCDS is to create database representations. Since it already defines relations between tables through keys, the structure and data can be easily taken into a database, and keeping the original structure would ease the transformation between the database and the official JSON format: from tables to CSV, and then from CSV to JSON.
A practical example for this comes from MIGA in Bolivia. They have been collecting procurement data on food products for the monitoring of public programs, and opted to load their data into a database with OCDS CSV-like tables. This would facilitate the transformations to OCDS, sharing their data when needed, and keeping everything in a database that will allow journalists and other less tech-savvy users to use the data without being familiar with JSON. Paraguay’s DNCP is also considering the possibility of offering a “database backup” version of their data using the tabular OCDS structure.
Challenges and considerations
Despite the advantages of this approach, there are some considerations to keep in mind if you want to implement it.
First, it is important to know that the names of the columns in the tabular format can get quite large for fields that are deeply nested. See the example of the image below, with shows the table for the contracts/implementation/milestones/documents block:
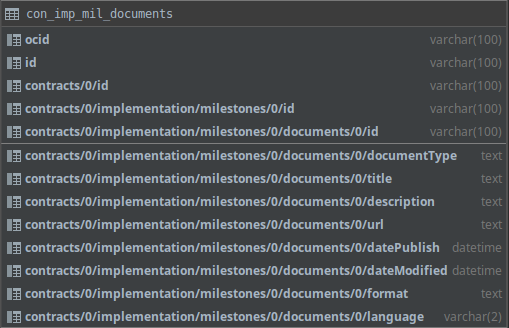
In most database engines, names of tables and columns are limited in length. The example in the image is from MySQL 5.7 which has a limit of 64 characters for both. The field:
contracts/0/implementation/milestones/0/documents/0/datePublished
has 65 characters already (and it’s not fully displayed in the image). Depending on the source data, it’s possible that you won’t reach the name limits of your database engine. But if you do, you should take provisions to ensure that the tables and column names are correctly generated when dumping data to CSV files.
Another challenge is with the Flatten Tool itself. Users have reported to have run out of memory when attempting to convert large volumes of data. To use this tool you will have to decide a sensible segmentation criteria to generate the JSON (release/record) packages. For example, you may not be able to generate a single package for a full year of data, so you will have to divide your data using another criteria, like by month or year and buyer.
Conclusions
Using a tabular OCDS representation to store and generate OCDS JSON can be a very useful approach in more than one scenario, as proven by the cases of Paraguay and Bolivia. We are hoping that more publishers find it useful, and help us learn what could be improved as well as what tools and techniques we could create together to make the publication and use of OCDS data easier.If you think this strategy might be good for you or your organization, get in touch with us! Send an email to [email protected] and we’ll be happy to assist you.