Exploring project identifiers for infrastructure projects

A guest post from Tim Davies on Open Contracting and Infrastructure research
In our last post on Open Contracting for Infrastructure, we looked at what we can learn from bringing together existing contracting and project data. In each of the cases we looked at, we had to carry out manual research to connect contracting processes to a particular infrastructure project. In this post, we document research into ways that project identifiers could be used to ease this process.
Project identifiers: opportunities and challenges
Although the Open Contracting Data Standard (OCDS) includes a ‘Project Identifier’ field, this is rarely used, and, even if it was populated, without new business processes to assign and validate identifiers to projects, there is little to guarantee it would be more reliable than checking against project names.
With an authoritative list of infrastructure projects in a country to draw on, and if the identifiers it assigned were used within contracting systems, it would be possible to automatically check which projects have published contracting information, and to analyse that data to identify projects where further scrutiny, monitoring and data collection should take place. So, as part of our research, we set out to explore whether there were established national or global practices for assigning identifiers to infrastructure projects.
We looked at the literature. We sought out commercial and community-driven infrastructure project databases. And we reviewed existing infrastructure transparency portals to check the identifiers in use. Ultimately, we found very limited uniform practice to draw upon, suggesting that any model for project identifier use will need to be sensitive to differences country-by-country.
Transparency portals and project IDs
In looking at existing CoST partner countries we found a range of practices in play to create a list of construction projects to monitor, including:
- Lists of projects by ministry in the national budget (Tanzania)
- Lists of ongoing projects, completed projects and projects under procurement published on the Ministry of Works, Transport and Communications website (Tanzania)
- A transparency portal developed by the Inter-American Development bank in coordination with government ministries (Costa Rica)
- Portals based on the CoST IDS and populated by ministries themselves (Honduras)
Across these cases, there were no examples where a unique project identifier was clearly assigned. In some cases there were:
- no identifiers at all (Ukraine)
- arbitrary identifiers, e.g. row numbers in a spreadsheet (Tanzania)
- identifiers which appeared to be assigned in the portal but not used elsewhere (Honduras)
In a number of cases, projects did appear to have a budget identifier, suggesting that it may be possible to find related contracting processes when the budgetary process goes down to the project level. However, the usability of this as a project identifier is vulnerable to changes in budget coding over time.
Exploring project registers
We found little evidence of robust national construction project registers that assign project identifiers. Responsibility for registers where they do exist appears to be at the Ministry level. However, without central registers, integration with procurement systems is likely to be complicated. And as a recent Open Data Institute report highlights, creating central data registers can require considerable work on both technology and governance.
In the United Kingdom we found the Major Projects Portfolio, but the public face of this appears to primarily be a spreadsheet download without identifiers. In Australia, the National Infrastructure Construction Schedule, appears to use post-codes as identifier fields, for example, WA 6104, NSW 2440 . Whilst using geography as an identifier might be a promising approach for physical infrastructure, there are many cases (such as long roads rather than junctions, or the identification stage of a project that might not yet have an agreed location) where it breaks down. In few cases, we found documented methodologies for assigning project identifiers and creating local project registers. For example, the California Department of Transport have a 10-digit ‘Project Identifier’ with a predictable format:
‘The first two digits of the Project Identifier represent the Charge District, the third and fourth digit represent the year the Project was created in the financial system (EFIS). The fifth through tenth digit represent a randomly system generated number’.
This instance points again to financial systems as the primary place where projects first enter into a ‘register’ of some form, and highlights that this might be the point at which a business process can pick up the creation of a project.
With wider scope, the Global Infrastructure Hub has been creating a ‘crowdsourced’ Projects Pipeline, although this is neither comprehensive, nor does it provide an identifier scheme for projects outside the database IDs given to entries in the pipeline dataset. We also explored a range of third-party projects databases, created by industry publications or international institutions. None appeared to have robust identifiers, and in the case of commercial databases, access to the underlying data about projects was restricted.
Other approaches to identification and registers
Having access to identifiers is not just a problem for infrastructure project transparency: it’s an issue across many different information management domains. We already deal with identifier issues in OCDS in a number of contexts, from setting out a pattern for contracting process identifiers (the ocid), through to using org-id.guide to encourage use of authoritative organisation identifiers. As part of our research we took a look at other identifier initiatives to see what could be learnt from these. These included:
- The Legal Entity Identifier (LEI). The LEI connects to key reference information that enables clear and unique identification of legal entities participating in financial transactions. The LEI is a 20-digit, alpha-numeric code based on the ISO 17442 standard developed by the International Organization for Standardization (ISO). It is maintained by the Global Legal Entity Identifier Foundation (GLEIF), and identifiers are assigned for a fee by delegated local operating units.
- Thomson PermID. PermID provides identifiers for Persons, Organisations, (Financial) Instruments and Quotes, based on the Thomson Reuters knowledge base. A search of the service did not locate suitable project identifiers.
- Digital Object Identifiers (DOIs). Part of the handle.net system, DOIs provide identifiers to publications and other resources. There has been UK research in construction to develop the use of Digital Object Identifiers (DOIs) for construction products. However, this research is only focused on products not projects.
- Bluenumber. Bluenumber is a commercial system (primarily used in Agriculture) to provide unique identifiers. The claim of Blue Number is to: “…uniquely identify people, organisations, places and things anywhere on Earth. Governments and businesses use bluenumbers to make policy and procurement decisions. NGOs and communities design targeted sustainability initiatives. Bluenumbers can show who produced the food for your table, made your clothes, or mined the metal for components in your phone or laptop.”. There is no evidence yet of Bluenumber being used for infrastructure projects.
These approaches range from ‘black box’ centralised systems (PermID), through to delegated identifier assignment linked to regulation and business models for maintaining identifiers and their associated registers of metadata (the Legal Entity Identifier). Where infrastructure is treated as an asset class, then it may in future come within the scope of projects like the LEI, although this does not appear to be the case at present.
Finding a way forward
At the conclusion of this rapid research project, we’ve not surfaced a universal approach to project identification that we can recommend, although we have found a range of practices that can be included in implementation guidance for Open Contracting for Infrastructure projects.
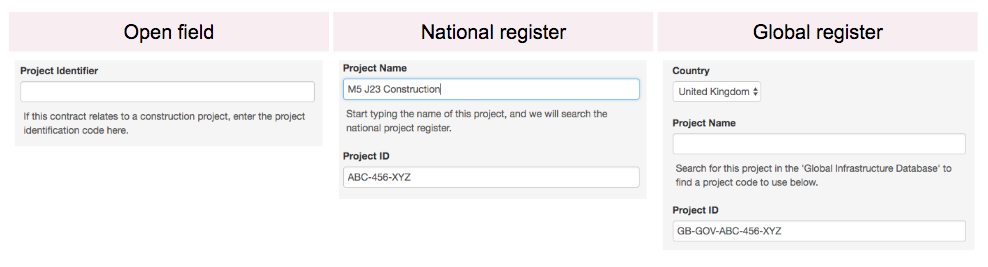
In essence, we see three main options, each requiring different levels of technical development and governance.
- Include an open field for project identifiers in procurement systems and work with each department entering data to make sure this is populated according to some defined pattern.
This would allow data quality queries to be run, checking, for example, that all the contracting processes over a certain value from a given agency have a project identifier, and that the identifier matches a known pattern or a local identifier list.
- National registers managed by a central agency, and integrated into procurement systems. In this model, officials entering procurement information would lookup a project from the national register, and have to request its addition if it was not already in the register. This would allow validation ‘at source’ of the project identifier – and would support checks on how many projects have no associated contracts.
- Global register modelled on the Legal Entity Identifier, and integrated through open APIs with procurement systems. In this model, countries could opt into an initiative to keep a global register of major infrastructure projects, and to record key project-level information about them. As with a national register, identifiers could be validated at source, and a consistent global dataset of infrastructure created.
Option 3 is, of course, highly ambitious, and we believe beyond the scope of any current work on Open Contracting and Infrastructure. Options 1 and 2 are open to countries to pursue, depending on the availability of a central actor, and the political will, to maintain a register – with technical options available for national registers to be implemented in a distributed way that respects departmental responsibilities. Ultimately, options 1 and 2 look relatively similar from the perspective on OCDS data that may be generated, and so the distinction will primarily emerge in adoption guidance.
Whilst consistent use of project identifiers could greatly ease the use of contracting process data for infrastructure transparency, there isn’t likely to be a one-size-fits-all approach to providing them. A ‘gold standard’ approach is likely to be unattainable for many, but a universal solution would have to take a ‘lowest common denominator’ track that holds implementers back from picking the best strategy available to them.
As we take forward this work, there are things that can be done through guidance on data creation and use in order to improve the use of project identifiers. Each individual implementation of OCDS, and of CoST, will need to give consideration to the context-appropriate strategy for project registers and identification, in order to have the best chance of supporting data-driven infrastructure transparency.