Meet Pelican, our new tool for assessing the quality of open contracting data

We’ve made significant progress in our approach to the quality of Open Contracting Data Standard (OCDS) data, since our last update in early 2018. We’ll give an update on what we’ve been up to, and then introduce our new data quality tool, Pelican.
Where we started from
The overarching hypothesis to our data work is that impact can result from OCDS data being published, regularly used and iteratively improved. As such, we want to see OCDS publications that at first meet a minimum level of quality, to then see those publications improve over time, and to see evidence of OCDS data being used to address real problems.
In terms of helping publishers to improve, until recently, we were focused on giving publishers feedback on any structural issues in their OCDS data, using results from the Data Review Tool. There were other types of quality issues we wanted to help publishers to correct, but the effort to measure and report on these was too intensive. We needed new tools.
Outlining a solution
We first sought a consultant to scope a new software project for measuring and reporting the quality of data that follows the OCDS. We selected Datlab, given their experience working with large volumes of procurement data and their familiarity with its quality issues, in particular as part of Digiwhist.
The result was a report in late 2018 that categorized types of quality, described a high-level architecture for the project, mocked up a dashboard for reporting quality, proposed a roadmap and estimate, and backed it all up with user stories based on conversations with OCP’s program managers and OCDS Helpdesk.
Building a solution
We couldn’t immediately put the report into practice, because we first had to complete work on a few of the project’s dependencies. First, Kingfisher is our internal tool for downloading, storing and pre-processing all publicly available OCDS data. By March 2019, it was ready to be used to feed data into the quality tool. Second, by May 2019, OCDS 1.1.4 was released, which better clarified some quality checks that OCDS data should pass.
We were then ready to launch a competitive process to hire a development team to define specific quality checks, and to write the software for measuring and reporting on them. We again worked with Datlab, and over the following months a list of over 100 quality checks was prepared (building on prior work by the OCDS Helpdesk) and the software was developed, with most checks implemented.
Some technical background
Before we discuss the solution in more detail, it’s useful to recap a few concepts in OCDS.
As you might already know, OCDS includes the concept of a “compiled release,” which expresses the current state of a contracting process. A compiled release is a JSON document that discloses information about the contracting process through field-value pairs. For example, here is a fictional excerpt of a compiled release, where status is one field and “complete” is its value:
"tender": {
"id": "ocds-213czf-000-00001-01-tender",
"title": "Planned cycle lane improvements",
"mainProcurementCategory": "works",
"status": "complete"
}
There are tens of millions of these compiled releases across all OCDS publishers, each of which might contain hundreds of fields, occupying about a terabyte of disk space (and growing). As such, our system was designed to handle large volumes of data, without exhausting computational resources. A message broker was used to coordinate data processing, with many workers each checking the quality of small amounts of data at a time.
What we measure
Our quality checks are segmented into four groups: field checks, compiled release checks, collection checks and time-based checks.
Field checks
Here, we primarily check whether a field is present or missing. If a field is missing, a user will be limited in what they can do with the data. For example, if data isn’t available on the number of bidders, then a user cannot analyze the competitiveness of the procurement market.
We perform a few other checks on individual fields. For example, if a field value should be a phone number or email address, we check that it is valid. If a field value should be a date, we check that it is not too far into the future (after 2050, e.g. 20019 is likely a typo for 2019) or the past (before 1970, e.g. 1019 is likely a typo for 2019).
The results of all field checks are reported on a summary page. Here is an excerpt of the first three fields in a compiled release.
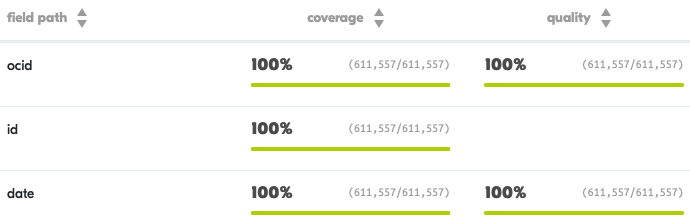
Each check has an individual page, through which users can preview data that passes or fails the check. Metadata is provided to describe any failures.
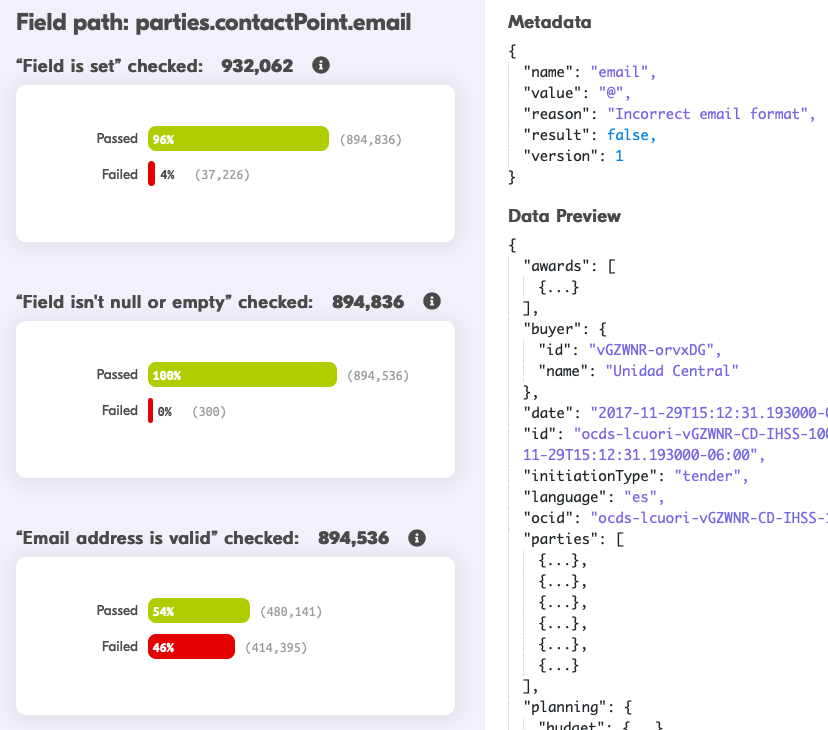
Compiled release checks
Here, our unit of analysis is an individual compiled release. There are three types of checks:
Coherence: The data should make sense. Examples of incoherence include:
- A time period has its start date after its end date
- An unsuccessful award has associated contracts
- An award date precedes bid submissions
- A sole source procurement has multiple bidders
Here is an excerpt of the summary page for the results of all compiled release checks. Like with field checks, users can click through to get more detail on any check.

Consistency: If the value of one field implies the value of another field, the values should be either identical or commensurate. Examples of inconsistencies include:
- The procuring entity isn’t assigned the role of ‘procuringEntity’
- The name of the procuring entity is different in different fields
- A time period’s duration isn’t the difference between its start date and end date
- A contract’s value is less than the sum of its related transactions’ values
Reference: Within a compiled release, some fields refer to others using identifiers. There is a quality issue if an identifier doesn’t match any target. For example:
- A contract’s awardID doesn’t match the id of any award.
Many other data quality tools stop at this unit of analysis, but we go a couple steps further.
Collection checks
Here, our unit of analysis is an entire collection of compiled releases. ‘Collection’ is the term we use to describe a data source at a single point in time: for example, all compiled releases from Colombia Compra Eficiente as of April 1, 2019. There are two main types of checks:
Distribution: The distribution of a field’s values should suggest no omissions or inaccuracies. For example, if all procurementMethod fields have a value of ‘open’, then the collection either omits or misreports other procurement methods; if all tender.status fields have a value of ‘active’, then the collection either omits or misreports non-active statuses.

Repetition: The repetition of a field’s values should suggest no data entry or data mapping issues. For example, if the contract value is $0 10% of the time, there might be an issue in how the data in the source system was mapped to OCDS.

There are a few less common types of checks:
- Uniqueness: Some fields’ values should be unique across the collection.
- Availability: A random sample of URL values should return no HTTP responses with error codes.
- Related processes: A related process reference field should have a valid target within the collection, and its title should be consistent with the target’s tender.title.
Time-based checks
Here, our unit of analysis is a dataset of compiled releases across time. Entire collections are compared to each other.
For now, we check that compiled releases remain available, and that newer compiled releases have at least the same number of stages as older compiled releases.

Overview
To cap it all off, an overview page for each collection highlights key facts and check results. For example, this visualization gives a quick idea of which contracting stages are covered.
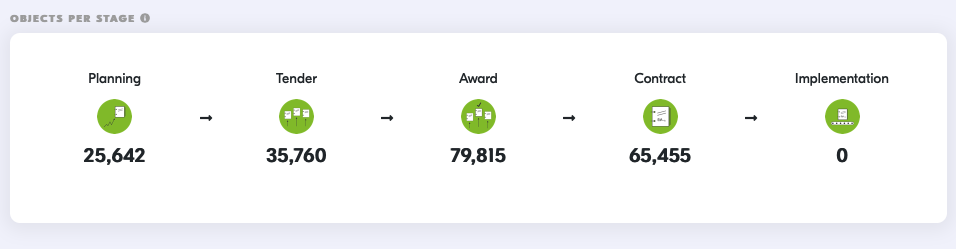
The future
Over the coming months, we will test and refine the tool internally, and integrate it into our existing processes for giving feedback to publishers. Based on input from colleagues and the OCDS Helpdesk, we will prioritize new features to implement in the new year, at which point the project will be made open-source.
The most exciting feature we are looking forward to is a report of the degree to which each dataset supports different use cases. Our Lead Data Analyst Camila has already started work to identify the information requirements of use cases like diagnosing the performance of a procurement market. Being able to indicate the purposes for which a dataset is suitable will provide both an incentive to publishers to improve quality in specific areas, as well as a guide to users to help them decide which datasets to use.
We look forward to sharing more frequent updates on our progress. If you have any questions about this work, please get in touch.